Abstract
While autonomous driving (AD) stacks struggle with decision making under partial observability and real-world
complexity,
human drivers are capable of applying commonsense reasoning to make near-optimal decisions with limited
information.
Recent work has attempted to leverage finetuned Vision-Language Models (VLMs) for trajectory planning at
inference time
to emulate human behavior, but the long inference time makes them impractical to deploy.
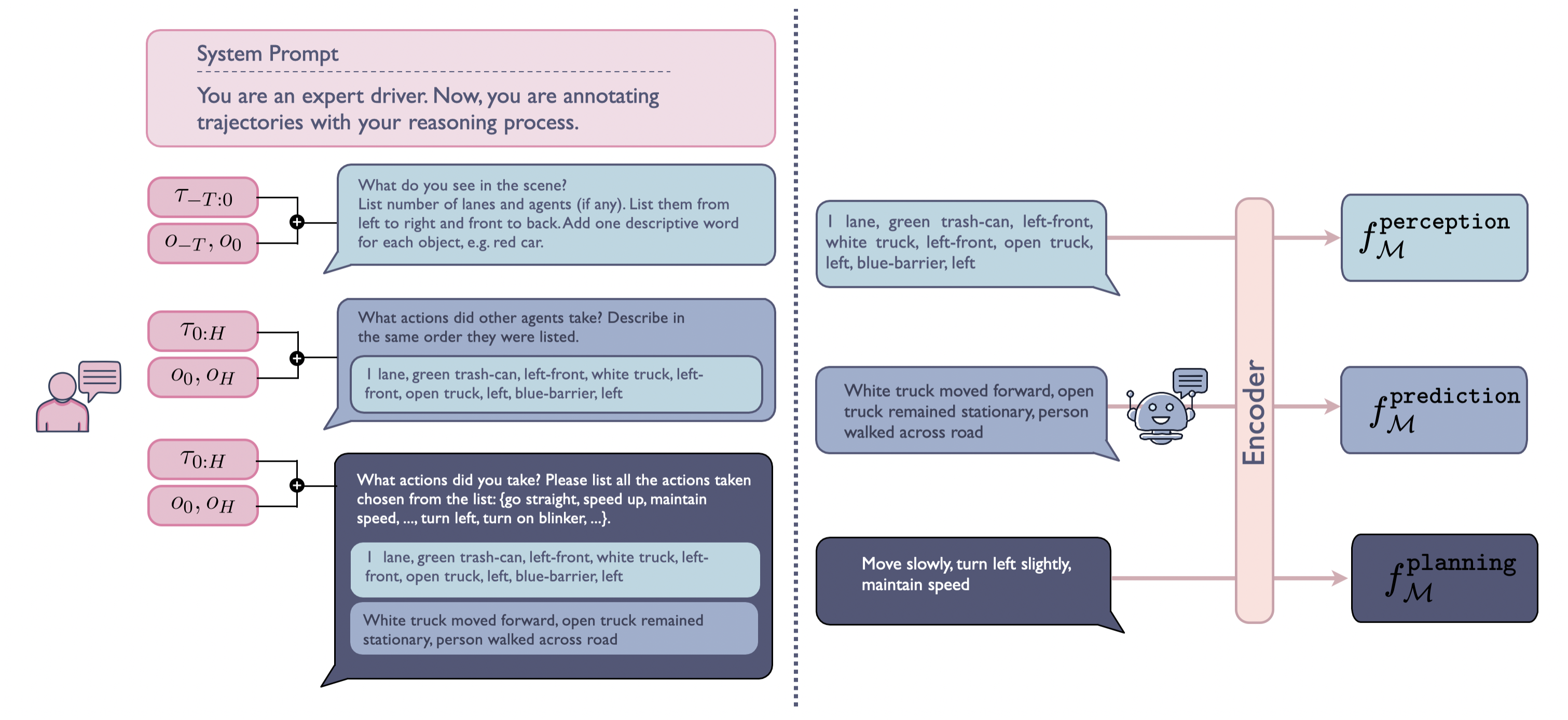
To bridge this gap, we propose VLM-Embedded Reasoning for
autonomous
DrIving (VERDI), a training-time framework that distills the
reasoning process
and commonsense knowledge of VLMs into the AD stack.
VERDI augments modular differentiable end-to-end (e2e) AD models by aligning intermediate module outputs at the
perception,
prediction, and planning stages with text features explaining the driving reasoning process produced by VLMs.
We validate VERDI in both open-loop (NuScenes and Bench2Drive benchmarks) and closed-loop (HugSim Simulator)
settings.
We find that VERDI outperforms existing e2e methods that do not embed reasoning by up to
11% in  distance and
11% in driving performance, while maintaining real-time inference speed.
distance and
11% in driving performance, while maintaining real-time inference speed.